Shredding یا تکه تکه کردن XML
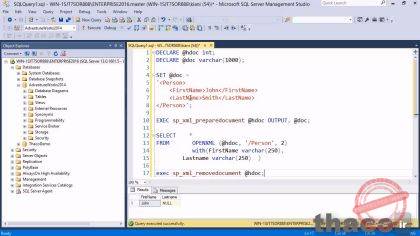
در این درس تخصصی، فرآیند shredding XML در SQL Server با استفاده از stored procedures مانند sp_xml_preparedocument و sp_xml_removedocument به همراه تابع openxml مورد بررسی قرار میگیرد؛ در این آموزش ابتدا متغیرهایی نظیر @hdoc و @doc تعریف شده و یک XML به صورت element با تگ اصلی شامل زیرتگهای و ساخته میشود، سپس با استفاده از openxml و دستور SELECT INTO این XML به یک جدول tabular تبدیل میشود. همچنین اهمیت رعایت دقیق case-sensitive بودن نام تگهای XML در همگامسازی با نام ستونهای جدول جهت جلوگیری از خطاهای استخراج داده به تفصیل توضیح داده شده است؛ به گونهای که این درس نه تنها مبانی تبدیل XML به دادههای جدولی را پوشش میدهد، بلکه نکات کلیدی برای بهینهسازی عملکرد و کاربرد عملی در پروژههای تخصصی SQL Server را نیز ارائه میدهد.
در یکی از ویدئوهای قبلی همین فصل، ما به دنبال تبدیل جدول داده های حاصل از یک دستور پایه ای select به فرمت کدهای xml در روش های attribute و element بودیم و حالا میخوایم با یک نگاه مخالفی نسبت به قبل پیش بریم و یک عملکرد برعکس رو داشته باشیم. یعنی ما الان میخایم با xml شروع کنیم و اون رو به جدول بر مبنای داده برگردونیم. بنظرتون این همه انعطاف پذیری در نرم افزار sql server 2016 می تونه کارآمد باشه یا خیر؟ این فرایند که ما درش یک کد xml رو به یک جدول داده تبدیل می کنیم، فرایند shredding ایکس ام ال یا بمعنی فارسی ریز کردن xml نامیده میشه. تبدیل xml به یه جدول یا همون فرمت tabular یا هر فرمت شی گرای دیگه ای که این فرمت بتونه در یک سیستم کامپیوتری برای انسان بصورت ویژوالی معنا دار باشه shredding نامیده میشه،انجام عمل shredding ، یکم از راههای دیگه و دستورات دیگه، پیچیده تر. مثلا وقتی میخواستیم فرمت داده جدولی یا همون table data رو به یکی از فرمت های xml تبدیل کنیم خیلی راحت این کار رو با اضافه کردن یه عبارت که شامل 3 کلمه میشد به انتهای دستور select انجام میدادیم.اما متاسفانه زمانی که میخوایم یک فرمت کد xml رو به فرمت table data یا بفارسی بگم، جدول داده ای تبدیل کنیم، این فرایند یکم پیچیده تر میشه، پس برای این نوع از کانورت ها یا تبدیلات دقت بیشتری رو داشته باشید.
مثل همیشه کدها رو به صورت طبقه بندی شده در فایلهای تمرینیتون قرار دادم.
شما همه اونها رو میتونین بردارین و راحت ازشون در همین فرمت تکستی که مشاهده می کنید کپی بگیرید و در یه پنجره query جدید قرار بدین و پیستشون کنید.
اجازه بدین قبل از این که این کدهایی که الان در این پنجره کوئری می بینید رو بخایم ران کنیم یکمی راجبش صحبت کنیم.
دو خط اول فقط declare و معرفی کننده متغیرهایی که بعدا میخوایم أزشون استفاده کنیم ، متغیرهایی از قبیل @hdoc و @doc، اگه بخام همین جا در مورد این دو متغیر توضیح بدم اینکه متغیر خط اول قراره یکسری داده ها رو از جداول int ما فراخونی کنه درست مقادیری که در خط دوم نوع اونها رو varchar تعریف کردیم.
خب؛ خط 4 تا 8 مجموعه مقادیر هر یک از متغیرها در برش و تکه xml رو برامون تنظیم کرده. در اینجا کد xml به صورت element هست که در جلسه های گذشته در موردش صحبت کردیم و یک المنت person رو تعریف کرده و اگه دقتتون رو بیشتر کنید می فهمید که قرار هست همین کدهای خط 4 تا 8 رو به یه جدول یا همون فرمت tabular تبدیل کنیم و درون این المنت person، firstname و lastname اون شخص یا person رو گذاشته، پس باید جدولی رو بوجود بیاریم که اسم سر ستون هاش یکی firstname و دیگری lastname باشه.
بعد از اون در خط 10 ما یه stored procedure اجرا میکنیم. در واقع در خط 10 با استفاده از کلمه کلیدی exec، از stored procedure که قبلا ساخته شده استفاده میکنیم. همونطور که میدونیم stored procedure یه چیزی شبیه توابع در sql هست که در اون میشه از دستوراتی مثه select وinsert و یا deleteاستفاده کرد. در stored procedure با استفاده از پارامترهای ورودی یا خروجی، از اون می تونیم اطلاعاتی رو بگیریم یا اطلاعاتی رو میتونیم به اون بدیم. قبلا اگه حضور ذهن داشته باشید در همین دوره آموزشی در ساخت اینstore procedure اون رو sp_xml_preparedocumen نامگذاری کردیم.
این یک ساختار برای stored procedureکه بعنوان ورودی برای برخیxml ها قرار داده میشه، و در واقع xml رو در دل این stored procedure بازسازی میکنه و نهایتاً در حافظه ذخیره میشه. همونطور که در خط های یک و دو هم دیدیم ما stored procedure رو دو متغیره تعریف میکنیم، متغیر hdoc که یک عدد صحیحه که به ما اجازه میده تا به داده درون حافظه در خط بعد دسترسی داشته باشیم و بعد از اون متغیر doc هست که فقطxml ای رو که ما به اون علاقه مند هستیم واینطور بگم xml ای که مد نظر ما هستش و الان هم می بینید که اونها در خطوط 4 تا 8 تنظیم شدن رو برامون می گیره و نگه میداره. بنابراین زمانی که stored procedure رو راه اندازی می کنیم ما یه xml در حافظمون داریم و سپس در خط 12 تا 15 همونطور که دیگه یاد گرفتین ما میتونیم یه دستور select رو اجرا کنیم، اما اینجا اگه دقت کنید بجای استفاده از دستورات select بهمراه from و نهایتاً اجرای کد برای گرفتن خروجی از یک جدول؛ اومدیم و از from بهمراه کلمه کلیدی openxml استفاده کردیم. همون طور که میدونیم و قبلا هم گفته شد xml ساده ترین راه برای تبادل داده بین برنامه هاست. اگه برنامه شامل چندین هزار خط کد xml باشه، تجزیه و pars کردن این تعداد خط کد خیلی دشواره. برای این منظور ما میتونیم از تابع openxml استفاده کنیم، تابع xml باید با دو تا stored procedure استفاده بشه: sp_xml_preparedocument وsp_xml_removedocument که زمانی که از sp_xml_preparedocument استفاده میکنیم در واقع اون رو در یک داکیومنت xml در حافظه اماده میکنه و زمانی که sp_xml_removedocument رو استفاده میکنه، منابعی رو که در ابتدا به دست گرفته رو ازاد سازی میکنه چون دیگه کارش تموم میشه. در واقع اس کیو ال سرور ساختار داخلی ای رو که ایجاد کرده، قطع میکنه. openxml دو پارامتر داره.اولین پارامتر داکیومنت xml هست که به عنوان یه پارامتر ورودی پذیرفته شده و دومین پارامتر یک پارامتر خروجی با نوع عدد صحیح هست در واقع زمانی که داکیومنتی با sp_xml_preparedocument اماده شد، openxml میتونه به یه مجموعه ردیف ترجمه اش کنه. به عبارت دیگه تابع openxml داده ای رو که در حافظه قرار داده میشه رو، توسط داکیومنت اماده stored procedure میخونه. بنابراین در اینجا در تابع openxml ، تعدادی پارامتر برای اون تعریف میکنیم، اولین پارامتر hdoc هست که نشون دهنده محل حافظ هست. بعد از تک کوتیشین، با یک اسلش و کلمه person، چون person ریشه عنصرxml مون هست و تگ اصلی کد xml مون تلقی میشه و اینطور میشه گفت که در واقع person نام جدول نهایی خروجیمون هست که دلیلش هم اینه که person در کد xml به عنوان تگ اصلی هست و همونطور که چند لحظه پیش هم اشاره کردم تگ های سطح پایین تر هم نام ستونهای جدول هستن و ما میخوایم یک سطح پایین تر از person رو با همه اطلاهات درون اون بخونیم و نهایتاً یک جدول أزشون ایجاد کنیم. من سعی میکنم که فیلد firstname و lastname رو که زیر قسمت person قرار دارن رو بخونم پس آخرین چیز برای اخرین قسمت عدد 2 رو تعریف میکنیم. که عدد 2 نشون دهنده اینه که در درجه اول در Xml از نوع elements ذخیره شده است. اگه داده شما در ابتدا در xml از نوع attributes ذخیره بشن شما میتونین عدد 1 رو تعریف کنین. بنابراین بعنوان یک قائده 1 برای xml از نوع attributes و 2 برای عناصر یا element قابل تعریف هستش. سپس در خط 14 و 15 فیلدها رو به صورت خاص جست وجو میکنیم. ما به دنبال فیلد های firstname و lastname هستیم. که دستور select از خط 12 تا 15 به ما جدول بر مبنای داده ای رو برمیگردونه و سپس خط 17، stored procedure دیگه ای بنام sp_xml_removedocument رو صدا میزنه و میاد و با اون داده ها رو از حافظه برمیداره. بنابراین چیزی رو که در حافظه قرار میدیم، به صورت اتوماتیک از حافظه حذف نمیشه و بنابراین نیازه که اون رو به صورت دستی پاک کنیم وگرنه فضای زیادی رو به هدر میدیم. بنابراین removedocument فقط اطلاعات رو که در حافظه قرار دادیم رو به اینصورت برامون پاک میکنه.
زمانی که همه این ها رو اجرا میکنیم فرمت جدولی یا tabular table رو برای ما برمیگردونه. ما الان می تونیم نام سرستون های FirstName و LastName رو که تگ های زیر شاخه کد xml با تگ ریشه ای person بودن رو ببینیم و اونچه که انتظار داشتیم رو می بینید که بهمون برگردوند و فرمت جدولی رو بهمون داد. بنابراین به صورت موفقیت امیزxml رو تکه تکه یا باصطلاح shredded کردیم و در فرمت جدول داده ای قرار دادیم.
به برخی موارد توجه کنید، برخلاف انعطاف پذیری و قابلیتهای زیاد موجود در sql، xml در حقیقتcase-sensitive هست یعنی به حروف کوچیک و بزرگ حساسه.
بنابراین به firstname و lastname توجه کنین. ما موارد مشابه در دستورselect رو به همان صورت که در xml مون دیده میشه،انطباق میدیم و دقیقاً از همون حروف بزرگ و کوچیک تعبیه شده در کد xml در دستورselect استفاده می کنیم.
اگه اون رو تغییر بدیم و در یه مورد تفاوت داشته باشه مثلاً بیام و اینجا در دستور select از حرف n کوچک در کلمه lastName استفاده کنم، در زمان اجرای query مطمئن باشین که نتیجه متفاوتی خواهد داشت.
خب ران می گیرم و همونطور که می بینید با اینکاری که کردم اون میگه که lastname مقدار null داره چون نمیتونه فیلد lastname رو پیدا کنه. چرا که اون الان ادغامی از حروف بزرگ و کوچیک کلمه lastname در تگ های کد xml و دستور select هست.
دستور select و دستور xmlما، به منظور گرفتن خروجی جدولی از داده های Xml، در حروف بزرگ و کوچک باید مطابقت داشته باشن.
همچنین هنگامی که شما این داده ها را در فورمت جدولی دارین، نسبتا راحت میتونین اون رو در جدول جدید قرار بدین.
ما فقط یک خط بعد از دستورselect اضافه میکنیم که بهش into میگیم. ما میخوایم select into برای ی جدول داشته باشیم.
پس اون به یک جدول جدید نیاز داره و می بینید که من اون رو همونfromxml نامگذاری کردم.
که نام جدول جدیدم هست. ما در حالی که قبلش اومدیم و حرف n رو در دستور select به حالت بزرگش تغییر دادیم اون رو اجرا میکنیم که میگه یک سطر تحت تاثیر قرار میگیره. همون چیزی که من انتظار داشتم.
و لیست tables رو باز میکنم و کلیک راست میکنم و رفرش رو میزنم و جدول جدید که fromxml نامگذاری شده رو میبینم.
روی اون کلیک راست میکنم و Top 1000 Rows رو انتخاب میکنم و میبینم که اون جدول جدید با ستون های مناسب مد نظرمون ایجاد شده و نهایتاً هم می بینیم که یک سطر از داده در جدول جدید قرار گرفتن.