ذخیره سازی XML
در این درس از دوره SQL Server، به بررسی روشهای ذخیرهسازی دادههای XML در پایگاه داده پرداخته شده است. در ابتدا، یک جدول نمونه با سه ستون مختلف شامل دادههای XML ایجاد میشود: یک ستون برای ذخیرهسازی دادههای XML بدون ارزیابی (untyped)، یک ستون برای ذخیرهسازی دادههای XML با ارزیابی استاندارد (typed) و یک ستون دیگر برای دادههای غیر XML. سپس نحوه استفاده از دستور INSERT INTO برای وارد کردن دادههای XML به جدول و تفاوتهای ذخیرهسازی انواع دادههای XML مورد بررسی قرار میگیرد. این آموزش همچنین شامل نکات فنی مربوط به مدیریت دادههای XML در SQL Server، تفاوتهای بین انواع ذخیرهسازی XML و بررسی چگونگی تعامل با دادههای XML از جمله نحوه ایجاد فضای خالی و نحوه ذخیرهسازی XML با استفاده از XML schema میباشد. هدف این درس فراهم کردن درک دقیق از نحوه ذخیرهسازی و مدیریت دادههای XML در SQL Server برای استفاده در پروژههای حرفهای و مهندسی است.
در این ویدوئوی اموزشی، ما قصد داریم درباره چگونگی ذخیره سازی xml در یک جدول sql server صحبت کنیم. در تمرین قبلی، ما یک جدول با نام xmltest ایجاد کردیم که سه ستون داره و یکی از اونها به صورت untype XML هست. به عبارت دیگه این ستون، XML ای هست که در برابر هر گونه مجموعه قوانین، ارزیابی نشده و استاندارد نیست. بعد از اون یک ستون به نام TYPED داشتیم که xml رو در برابر یک xml schema ارزیابی شده، که اون رو هم با نام testSchema ایجادش کردیم، ذخیره میکنه و بعد از آپدیت خروجی مد نظر با این نوع از استاندارد رو بهمون ارائه میکنه.
و بعد از اون یک ستون به نام justTest ذخیره شد که ضرورتی برای ذخیره xml نداشت و هر نوع متنی رو میتونست ذخیره کنه.
من برخی کدها رو برای شما طبقه بندی کردم تا عمل درج یا همون insert رو باهاشون انجام بدیم و نهایتاً خروجی های ستون های مختلف این جدولی که در ویدئوی آموزشی قبلی ایجادش کردیم رو ببینیم.
بنابراین اگه میخواین اونها رو از فایلهای تمرینیتون بردارین و در یک پنجره query جدید کپی کنین.
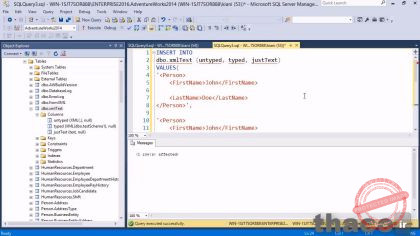
درابتدا اجازه بدین که قبل از اجرا راجبش صحبت کنیم. اولین خط INSERT INTO رو بیان میکنه. همون طور که در بخشهای قبلی گفتیم INSERT INTO یک ترکیب استاندارد، برای قرار دادن سطرهای جدید هستش. سپس در خط 2 نام جدول یعنی XmlTest و نام ستونهایی که میخوایم درون اون ها عملکرد INSERT INTO رو قرار بدیم، وجود داره. بعد از اون در باقی مونده کُدم مقادیری قرار دارن که من دقیقا مقدار مشخصی که در این کدهای XML وجود داره رو برمیدارم و در 3 ستون قرار میدم.
پس تا اینجای کارم مشخص هست که میخام برای هر سر ستون جدول XmlTest ام یکی از این کدهای xml رو وارد کنم و نتایج خروجی هر سر ستون که برای یک نوع از خروجی های Xml تعریف شده رو با هم مقایسه کنم.
این یک XML معتبر هست که قوانین schema xml ما که در ویدئوی آموزشی قبلی طرح اون رو تعریف کردیم رو برامون برآورده میکنه و در واقع در برابر این قوانین ارزیابی شده است. بنابراین باید خوب کار کنه.
همچنین توجه داشته باشین که بین اونها یک فضای خالی وجود داره و اونجا هم یک خط خالی دیگه، بین Firstname و Lastname هم هست. بسیاری از این فیلدها، فضای خالی رو حفظ میکنن و بعضی دیگه هم حفظ نمیکنن.
بنابراین پیش میریم و کُد رو اجرا میکنیم. نتیجه ای که داده میشه میگه یک سطر تحت تاثیر قرار گرفت و این دقیقا همون چیزی هست که انتظار داشتیم. بنابراین ما برخی داده ها رو در جدولمون داریم که میخوایم در حال حاضر یک نگاهی به اونها بندازیم.
من رویxmltest راست کلیک میکنم و select top 1000 rows رو میزنم.
نتایج رو در زیر قسمتهایuntyped و typed دقیقا به صورت مشابه برای هر دو میبینیم. میتونیم روی اونها کلیک کنیم و جزییات رو برای این نوع از xml ببینیم. توجه کنین که در اینجا خطوط خالی پاک شدن و این یک چیز رایجی هست برای وقتی که یک داده ای رو به عنوان xml ذخیره میکنیم.
در واقع نهایتاً دستگاه تمام داده های معنی دار رو حفظ میکنه و اگه فضای خالی زیادی داشته باشیم یکم طول میکشه تا دستگاه بیاد و اونها رو بیرون بکشه و حذف کنه؛ ولی نمیتونیم بگیم که وجود فضای خالی زیاد یک مشکل بزرگ هست چون بطور معمول به یک همچین چیزهایی برخورد می کنیم و اونقدرها هم مهم نیست.
من این رو میبندم و با اسکرول این پایین به سمت راست حرکت میکنم و ستونjusttext رو میبینم وهمانطور که مشاهده میکنید گزینه ای برای کلیک در زیر justtext نداریم تا اطلاعات بیشتر رو مشاهده کنیم. پس برای اینکه بخایم به جزئیات بیشتری دست پیدا کنیم من میخوام برخی چیزها رو در Management Studioعوض کنم.
به صورت نرمال Management Studio این داده ها رو به صورت پیش فرض برای یک grid یا همون results to grid برمیگردونه اما به جای این، من میخوام داده ها رو به صورت متن برگردونه یا به اصطلاح میخوام در حالت result to text باشه. بنابراین در toolbar یک آیکن وجود داره که به نظر میرسه به صورت 0 و یک است و یک فلش ابی روی اون قرار داره و زمانی که یکم ماوس رو، روی اون قرار بدیم، عبارت Results to Text رو نشون میده . روی اون کلیک میکنم و بعد از اون دوباره query رو اجرا میکنم .
این بار نتایج یکم متفاوت شد. در واقع، اون داده مشابه رو داره، که فقط فرمتش متفاوت هست و میبینیم که برای سرستون untyped این نوع جدول متنی همه xml رو در یک سطر برگردونده.
هنوز ساختار xml رو داره اما فضاهای خالی سفید بین تگ های اصلی و سطح پایین رو بیرون کشیده، دقت کنید اینی که این پایین تره مربوط به سرستون untyped نیست و چند لحظه دیگه در موردش کامل توضیح میدم، اگه به سمت راست برم چیزهای مشابه رو برای typed بعنوان سر ستون دومم میبینم و همه این ها داده های مورد علاقه ما طبق همون استاندارد و طرحی که در ویدئوی آموزشی قبلی تعریف کردیم، در اینجا هستن با این تفاوت که فضاهای خالی بیرون کشیده شدن و اگه باز هم به سمت راست برم، در قسمت نوع داده یا همون سر ستون justText، به جای نوع دادهxml ، نوع داده متنی یا همون text ذخیره شده.
در این جا فقط واژه person رو میبینم و این به خاطره این است که فرمت رو حفظ کرده. اون بازگشتهای سختی رو در اینجا حفظ میکنه بنابراین قطعه xml باقی مونده، در خط بعد وجود داره.
به سمت چپ میرم و میبینم که باقی مونده xml مربوط به سرستون justText در اینجا درست یک خط پایین تر از نتایج سرستون untyped حتی با خطوط خالی بین المنت های firstname و lastname اومده. اگه شما نیاز داشته باشین xml رو وارد کنین و ساختار رو هم به درستی وارد کنین که شامل همه فضای سفید هم بشه و فضاهای سفید هم وجود داشته باشه، پس احتمالا میخواین ازtext data type استفاده کنین اما این نوع رخداد نادر است و در طول این سالها کمتر کسی رو دیدم از این نوع نحوه ذخیره سازی بخاد استفاده کنه و اونهایی از این استفاده می کنن که نگهداری فضای سفید براشون مهم باشه.
بنابراین رایجتر این است که ما برای ذخیره xml از XML data type استفاده کنیم.
اجازه بدین به تبی که در اون insert رو انجام دادیم برگردیم. به یاد داشته باشین که تکه دوم ازxml که ما میخواستیم در مقابل xml schema معتبر بمونه درست اینجا هستش پس اگه ما سعی کنیم که کُد xml ای که قرار است وارد سر ستون دوم جدول بشه رو طوری قرار بدیم که قوانین رو براورده نکنه و مطابق با قوانین و xml schema ای که در ویدئوی قبلی تعریف کردیم نباشه، اون حتما باید با شکست مواجه بشه. بنابراین به جای lastname واژه last رو در هر دوی این المان ها جایگزین میکنم و دوباره اون رو امتحان میکنم که باید ارر بده و بله اون انجام شد و در حقیقت میگه ارر در validation xml هست یعنی اعتبار سنجی با اونچه که ما بعنوان استاندارد در ویدئوی آموزشی قبلی براش تعریف کردیم الان ساقط شده.
بدین صورت که محتوای نامعتبری داره و میگه که انتظار میرفت که عنصر LastName پیدا بشه اما به جاش last پیدا شد.
بنابراین یک پیغام خطای توصیفی مناسبی است. اون میگه که اون چیزی که دنبالش بودم پیدا نکردم؛ اما بجاش این رو پیدا کردم. بنابراین این پیغام یکم بهتر از پیغام، خطاهای با گویایی متوسط هستش که در اینجا ما این پیغام جالب رو دیدیم.
به case sensitive که حساسیت به حروف بزرگ و کوچیک هست هم توجه کنین. اگه ما lastname رو با حروف کوچیک داشته باشیم اما چون مشابهش اونطور که در طرح یا schemaمشخص شده وجود نداره، ارر میده، حالا اگه بجای n بزرگ در lastname، n کوچیک قرار بدم، و أزش اجرا بگیرم حالا میگه که من انتظار داشتم lastname با حرف بزرگ nباشه چون اینطور برام تعریف کرده بودین، اما الان با حرف کوچیک n برای من وارد کردین و من lastname رو با n کوچیک پیدا کردم و این خوب نیس و برای انطباق باید حرف بزرگ اون رو داشته باشیم.
اگه اون رو درست کنم و ما دوباره اون رو اجرا کنیم؛ حالا اون میگه که یک سطر تحت تاثیر قرار گرفت. ما عمل insert رو به صورت موفقیت امیزی انجام دادیم. اولین برش کد xml ای که من از فایل های تمرینی پیست کردم در ستون untype درج شده است که داده در مقابل schema یا همون طرح معتبری قرار نگرفته، بنابراین ما option های زیادی داریم و در واقع چیزی که شامل lastname باشه رو در نتایج جدولمون نداریم.
ما میتونیم به طور کامل اون رو از بین ببریم و میتونیم اون رو اجرا کنیم. و اون هنوز کار میکنه. اون هر چیز معتبری رو از xml میگیره و زمانی که xml، untype باشه، مهم نیست که ایا شما قوانین schema رو در کد xml ای که میخاین أزش خروجی جدولی بگیرید دارین و رعایت کردین یا نه.