طریقه ایجاد یک index
این درس، که بخشی از دوره جامع SQL Server Essential Training در وبسایت طهاکو است، به بررسی تخصصی فرآیند ایجاد ایندکس در SQL Server میپردازد. در این آموزش، اهمیت ایندکسها برای بهبود عملکرد و بهینهسازی زمان واکشی دادهها به وضوح بیان شده و تفاوتهای کلیدی بین clustered index و non-clustered index همراه با مزایا و محدودیتهای هر کدام مورد بررسی قرار میگیرند. همچنین، روشهای ایجاد ایندکس با استفاده از T-SQL و دستور CREATE INDEX از طریق مثالهای عملی ارائه شده تا متخصصان بتوانند با بهکارگیری این تکنیکها، ساختارهای ایندکس را به شیوهای بهینه و کارآمد در محیطهای واقعی پیادهسازی کنند.
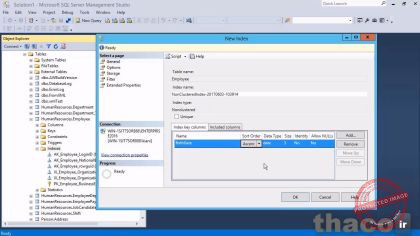
اکنون من میخوام طریقه ایجاد یک ایندکس رو بهتون نشون بدم. اینجا در Management Studioمن میخوام پایگاه داده AdventureWorks2014 رو باز کنم و بعد از اون Tables رو باز میکنم و ما میخوایم به HumanResources.Employee یک نگاهی بندازیم. اون جدولی هست که قبلا در ویدئوهای آموزشی قبلی باهاشون کار کردیم. اون رو هم میام و باز میکنم و در زیر اون، یکی از ایتم ها، Indexes هست. اگه ما اون رو باز کنیم، میبینیم که یک مشت از ایندکسهایی هست؛ که در حال حاضر ایجاد شده و حالا، من قصد دارم یک ایندکس جدید رو ایجاد کنم. من میتونم روی اون indexes راست کلیک کنم که بالاترین ایتم new index هست.
سپس اون با منویی که برام باز میکنه داره، از من برای نوع index میپرسه در واقع از من میپرسه که دوست دارم نوع ایندکسم چطور باشه، اگه دقت کنید این لیستی از تمام انواع ایندکس هایی هستش که من در ویدئوی آموزشی قبلی درموردشون باهاتون صحبت کردم. من فعلا میخوام با Non-Clustered Index پیش برم، یعنی بیام و یکسری اطلاعات خاص از این جدول مد نظرم رو مرتب کنم. در صفحه ای که باز میشه، یک فیلد برای table name داره که من نمیتونم تغییرش بدم. اون خاکستری رنگ شده. بنابراین با این تفاسیر هم میشه مطمئن شد که در حال حاضر جدولی که انتخاب شده، جدول employee هست. پس یک فیلد برای name index داره و به صورت پیش فرض نامی رو که من میخوام گذاشته. حالا اگه شما دوست دارید، میتونین اون رو تغییر بدید. سپس، اون از من نام ستونهایی که میخوام اضافه کنم رو درخواست میکنه. بنابراین من روی دکمه add کلیک میکنم. من فقط میخوام یک ستون برای این یکی اضافه کنم. ستون BirthDate، و روی دکمه اوکی کلیک میکنم.
و اون همونطور که می بینید داره میگه که، اون رو میخوام به صورت صعودی یا همون Ascending قرار بدم و سفارشیش کنم، من اگه بخوام، میتونم اون به صورت نزولی یا Descending هم تغییر بدم. ولی من اون رو به همون حالت Ascending میذارم بمونه. بنابراین این index یک ساختار داده مجزا خواهد داشت. اون به صورت مجزا و جدا از جدول ذخیره میشه. اما اون شامل یک کپی از ستون BirthDate هست و این ستون جدید بصورت صعودی در حالی بوجود میاد که اون ستون به همون حالت اولیه اش یعنی در همون جدول HumanResources.Employee بصورت ذخیره شده و دست نخورده باقی می مونه. بنابراین اگه ما بخوایم که یک query اجرا کنیم که می دونیم ممکنه بهش به دفعات زیاد در کارمون نیاز داشته باشیم و در اون کوئری به دنبال یک شخص کارمند با بزرگترین یا کوچکترین تاریخ تولد باشیم، پس در این زمان هست که این ایندکس خیلی ارزشمند میشه.
با استفاده از این ایندکس، دستگاه میتونه اطلاعات رو خیلی خیلی سریع پیدا کنه. بخصوص اینکه ما می دونیم که در کارمون به این اطلاعات بکرات نیاز داریم و این ایندکس باعث میشه که ما در کارمون سریع تر باشیم. همه اون کاری که دستگاه در این نوع بررسی با این نوع از ایندکس نیاز داره انجام بده این هست که، بالاترین و پایینترین سطر رو بخونه، و نهایتا خیلی سریع، بزرگترین و کوچکترین تاریخ تولد یا همون birth date رو به ما تحویل بده. که به وضوح سریع تر از خوندن هر سطر در جدول هست. یکی از گزینه هایی که من دوس دارم به شما نشون بدم، گزینه storage در پانل سمت چپ این پنجره هست و اون از من می پرسه که دوست دارم ایندکسم در چه Filegroup ای ذخیره بشه. من تنها یک Filegroup توی دیتابیسم دارم که PRIMARY هست.
اما اگه شما چند Filegroup توی database تون داشته باشید، شما میتونین index رو توی یک Filegroup متفاوت از جدول هاتون ذخیره کنین و در برخی موارد میتونین یک برتری درعملکرد ارائه بدین و عملکرد بهتری داشته باشین. بنابراین روی دکمه اوکی در این صفحه کلیک کنین. حالا به indexes برین و روی اون راست کلیک کنین و ایتم پایین، یعنی رفرش رو مثل همیشه بزنین و حالا ما Clustered Index جدیدمون رو میبینیم که چند لحظه پیش ایجادش کردیم. بنابراین به نظر میرسه که این کارمون برای تعریف یک ایندکس جدید موفقیت آمیز بود.