بررسی execution plans
در این درس تخصصی، با بررسی دقیق Execution Plan در SQL Server 2016، فرآیند اجرای کوئری از ابتدا تا انتها تحلیل میشود؛ از مشاهدهی مراحل اولیه مانند Clustered Index Scan و Sort که هزینهی قابل توجهی از منابع سیستم را مصرف میکند تا شناسایی Missing Index و استفاده از Display Estimated Execution Plan در Management Studio برای استخراج جزئیات مربوط به ایندکسهای پیشنهادی. با اصلاح و پیادهسازی اسکریپت Missing Index، نحوهی تغییر مسیر اجرای کوئری از عملیات پرهزینهی sort به یک Index Seek (NonClustered) نشان داده میشود که باعث کاهش چشمگیر CPU Cost از 2.4 به 0.06 شده و بهبود عملکرد کوئری را بهصورت ملموس به مخاطب منتقل میکند؛ این درس پایهای برای درک عمیقتر بهینهسازی و تحلیل عملکرد کوئریها بوده و پس از مشاهده ویدئو در یوتیوب، درک جامع و کاربردی از مفاهیم ارائه شده حاصل خواهد شد.
در این ویدئوی آموزشی میخوایم راجب به execution plansصحبت کنیم. وقتی که ما Execution Plan رو خوب بشناسیم توانایی بالایی توی رفع مشکلات کوئری ها مانند کندی سرعت کوئری، استخراج عملگرهای نا مناسب و … به دست خواهیم اورد. زمانی که شما یک کوئری برای مایکروسافت اس کیو ال سرور 2016 ارائه میدین، دستگاه با یکسری از مراحل، درمورد چگونگی انجام این کار جلو میاد. این سری از مراحل، یک execution plan نامیده میشه و ما چون میتونیم execution plan رو ببینیم پس می تونیم بیایم و با استفاده از انالیز و تجزیه تحلیل اون مراحل، گاهی اوقات، مکانهایی رو که اغلب میتونن با ایجاد indexes، کوئری رو بهبود ببخشن، پیدا کنیم، و با تعریف ایندکس مورد نیاز اون مکان خیلی راحت برای سرعت بخشیدن به اجرای کوئری هامون اقدام کنیم، بنابراین من بعضی کدها رو که برای این کار میخوام، رو از قبل براتون طبقه بندی کردم.
این کدها در فایل تمرینی تون وجود دارند. اگه شما می خاین که اونها رو بردارین و أزشون برای امتحان کردنشون استفاده کنید، اونها رو کپی کنین و توی یک کوئری جدید در Management Studioپیست کنین، و همونطور که می بینید این نسبتا یک دستور select سرراست هست.
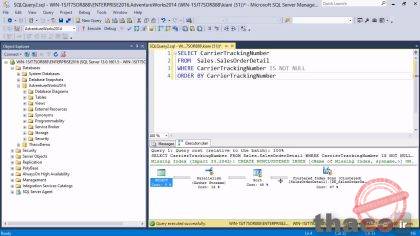
ما میخوایم یک ستون رو انتخاب کنیم که در جدول Sales.SalesOrderDetail، CarrierTrackingNumber نامیده شده. من میخوام تنها سطرهایی رو برگردونم که CarrierTrackingNumberشون، NOT NULLهست یعنی مقدار داره و ما میخوایم اون رو با ستون CarrierTrackingNumberمرتب کنیم. اگه ما اون رو اجرا کنیم، میبینیم که حدود 60,000 سطر برگردونده میشه.
و این بدین معنی هست که دستگاه 60000 مقدار مشخص رو مرتب کرده. یک کامپیوتر قدرتمند، احتمالا خیلی سریع میتونه این تعداد رو، مرتب کنه! اما اگه شما میلیون ها، یا دهها میلیون ردیف و رکورد برای مرتب کردن داشته باشین، چطور؟
اون میتونه تبدیل به یک بحران بشه!
بنابراین اجازه بدین که ببینیم چطور میتونیم اون رو بهینه کنیم؟ در ابتدا، ما میخوایم که یک نگاه به execution plan بندازیم. یک دکمه درtoolbar وجود داره که Display Estimated Execution Plan نامیده میشه، اون توی نوار ابزار، معمولا در همون نواری هست که علامت تعجب قرمز وجود داره و کلمه execute هم در کنارش دیده میشه.
اون، دو یا سه دکمه سمت راست ترش هست و اگه ما روی اون کلیک کنیم؛ سپس در پایین کوئری، یک براورد از execution plan میبینیم. اگه به علامت فلش ها دقت کنید متوجه میشید که این چیزها از راست به چپ خونده میشن. بنابراین اولین گام اون ایتمی هست که سمت راست هست، اون Clustered Index Scan هست و اون به ما، نام ایندکسی رو که میخوایم بخونیم، میگه. بعد از اون، این فلش نشون دهنده این هست که به مرحله بعد منتقل شده. در این نقطه، تقریبا 66000 ردیف از داده ها وجود داره.
و ما به مرحله بعد منتقل میشیم. جایی که داده ها مرتب شدن و اسم این مرحله هم sorted هست و ما میبینیم که sort یک cost به اندازه 63% داره. بنابراین 63% از کل کارهای انجام شده توی این کوئری، صرف عملیات مرتب سازی شده. این هم همینجا بهتون بگم که کل 100 درصد کاری که در مراحل مختلف انجام شده بصورت دقیق در این چند مرحله تقسیم شده و ما می تونیم درصد کاری که برای هر مرحله مورد نیاز بوده رو ببینیم و اگه ما ماوس رو بیشتر روی اون نگه داریم اطلاعات بیشتری رو بهمون نشون میده. Estimated CPU Costبرابر با 2.4. بنابراین 2.4 واحد از پردازندمون استفاده شده و ما میخوایم سعی کنیم که این واحد استفاده شده از پردازنده رو کاهش بدیم.
بعد از مرتب سازی به parallel taskیا کار موازی میرسیم جایی که داده هایی که تقسیم شدن، دوباره پیوند داده میشن شدن، و بعد از اون داده، به دستور select، انتقال داده میشه و بعد از اون داده برای ما در Management Studio بازگردونده میشه. همچنین شما توجه کنین که در این قسمت execution plan، یک عبارتی با نام Missing Index وجود داره. اگه روی عبارت Missing Index کلیک راست کنیم، میتونیم به Missing Index Details بریم. اون یک new query باز میکنه.
و همونطور که می بینید این اغاز یک دستور برای ایجاد index پیشنهادی هست. در حال حاضر، متن خارج از تعبیره و به صورت کامنتن، یعنی بصورت مخفی و غیر کارآمد اینجا نشون داده میشه، بنابراین ما باید، علائمی رو که باعث شده، این تبدیل به کامنت بشه رو پاک میکنم و یکی دیگه از چیزایی که باید پاک کنیم، name هست، که مال من که میخام أزش استفاده کنم فکر کنم testIndex، براش، مناسب باشه و حالا که ما این ایندکس پیشنهادی برای رفع مشکلات سرعت اجرای کوئری تعریف کرده ایم، بهتر هست ببینیم که این ایندکس پیشنهادی چه تاثیری بر روند عملکرد اجرای همون کوئری داشته. ما میتونیم پیش بریم و اون کوئری رو اجرا کنیم. پس من به کوئری قبلی برمیگردم و اون رو دوباره اجرا میکنم و بعدش هم برای دیدن تاثیر مد نظرم روی Display Estimated Execution Plan دوباره کلیک میکنم.
و حالا ما میبینیم که فرایندمون خیلی کوتاهتر شد، چون داده ها در حال حاضر در اون index بخوبی ذخیره شدن. بنابراین دستگاه، دوباره نباید اون رو مرتب کنه. بنابراین ما هیچ مرحله sort ای رو در این فرایند نمیبینیم. ما همچنین میبینیم که اون در حال خوندن index هست. اون میگه که من میخوام یک Index Seek روی
(NonClustered) [SalesOrderDetail].[testIndex] انجام بدم. بنابراین، ما میدونیم که اون از یک index جدید که ما فقط اون رو ایجاد کردیم، استفاده میکنه. ماوس رو بصورت شناور روی اون قرار میدم و ما حالا میبینیم که Estimated CPU Cost، 0.06 هست.
بنابراین ما از واحد 2.4 cpu استفاده شده به 0.06 واحد استفاده شده رسیدیم. به عبارت دیگه، استفاده از واحد پردازش سیستم مون خیلی نزدیک 0 هست. بنابراین ما، در مقدار cpu لازم، مقدار قابل توجهی، صرفه جویی داشتیم. بزرگترین صرفه جویی از این واقعیت نشأت میگیره که اون داده ها میخاستن به صورت بلادرنگ مرتب بشن. به همین دلیل هم ما اومدیم و یک index ایجاد کردیم، و همونطور که می بینید اکنون داده ها برای ما از پیش تعریف شده اند و این خیلی در بالا بردن کارایی و سرعت ما تونست، موثر باشه.