ایمپورت و اکسپورت اطلاعات Unicode
در این درس از آموزشهای ضروری SQL Server، به موضوع حیاتی وارد کردن و صادر کردن دادههای یونیکد پرداخته میشود. با توجه به اهمیت پشتیبانی از زبانهای مختلف و کاراکترهای خاص در پایگاههای داده، این درس به شما نشان میدهد که چگونه با استفاده از ابزارهایی مانند BCP و دستور BULK INSERT، دادههای یونیکد را به درستی مدیریت کنید. با یادگیری تکنیکهایی مانند استفاده از سوئیچ -w در BCP و تنظیم DATAFILETYPE در BULK INSERT، قادر خواهید بود دادههای چندزبانه را بدون از دست دادن اطلاعات وارد و صادر کنید. این مهارت برای هر متخصص پایگاه داده که با برنامههای بینالمللی سروکار دارد، ضروری است و با تماشای ویدیوی این درس، درک عمیقتری از این فرایندها به دست خواهید آورد.
در حال حاضر من میخوام به داده هایی یک نگاه بندازم که از داده هایی که قبلا باهاشون کار کردیم، یکم پیچیده ترن، و در واقع، زمانی که ما این داده ها رو export میکنیم، برای اولین بارمون یک ارر حتما خواهیم داشت که در این ویدئوی آموزشی میخام نشونتون بدم که چطور اون ارر رو رفع کنیم. بنابراین، من روی AdventureWorks2014 کلیک راست میکنم و بعد task رو انتخاب میکنم و بعد از اون export data رو انتخاب میکنم. در صفحه اول، روی next کلیک میکنم. Data Source، sql server محلی هست، بنابراین، SQL Server Native Client 11 رو، انتخاب میکنم. بعد از اون نام مناسب برای sever در قسمت server name و نام مناسب برای database انتخاب کنین.
روی دکمهnext کلیک میکنم. مقصد یا همون destination دوباره یک flat file خواهد بود. من میخوام اون رو در همون دایرکتوری پیشفرض قرار بدم. یعنی در مسیر MS SQL و dataبعد هم اسمش رو PersonExport میذارم. این اسم رو به این دلیل میذارم چون من میخوام از جدولperson ، export کنم. روی next کلیک میکنم. در این مرحله میخوام چک باکس copy data from one or more tables بصورت انتخاب شده باشه و next.
قسمت source table هم، Person.Person خواهد بود. روی next کلیک میکنم. من با پیش فرض run immediately پیش میرم و روی دکمه next کلیک میکنم و بعد از اون روی دکمه finish.
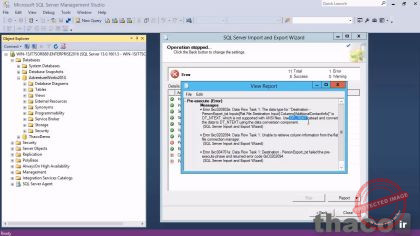
چند task اول با موفقیت انجام شده اما به یک ارری رسیده و روی خطی که ارر داده، ما یک message داریم. من پیش میرم و روی اون کلیک میکنم و message میگه که نوع داده برای destination، DT_INTEXT هست که با فایلهای ansi پشتیبانی نمیشه و اون میگه که از DT_TEXTبه جای اون استفاده کنین. DT_INTEXT یک فیلد یونیکد هست و DT_TEXT یک فیلد non-unicode.
یونیکد یک روش برای ذخیره داده های متنی است که اجازه استفاده از علایم لهجه بیشتر و کاراکترهای خاصی که در انگلیسی رایج نیستن، ولی ممکنه در زبانهای دیگه رایج باشن، رو میده. و در مجموع این رایجترین مشکلی هست که با import و export کردن داده ها داریم. اگه source، از unicode کردن استفاده کنه و destination از unicode استفاده نکنه، ما یک مشکل خواهیم داشت، امیدوارم، شما بتونین هر دو منبع source و مقصد distination رو برای استفاده کردن یا نکردن از unicode تنظیم کنین، تا زمانی که اونها با هم مطابقت کنن. همه چیز معمولا به ارامی و در حالت نرمال خودش پیش میره.
اما زمانی که یکی در حالت unicode هست و دیگری در این حالت نیست، همه چیز به صورت معمول و هموار حرکت نمیکنه و ما به یک پیغام خطا مثل این میرسیم. تا زمانی که برای یک فایل از نوع تکستی این موضوع رو اعمال نکنید حتما با این ارر مواجه خواهین شد. من میخوام این صفحه رو ببندم و بعد از اون، توی wizard، روی دکمه back کلیک میکنم. چندین بار این کار رو انجام میدم، تا به صفحه ای میرسم که در اون میومدم و destination رو انتخاب می کردم و درست در زیر اون باکس brows ای که ما برای تعیین موقعیت فایل مون أزش استفاده کردیم، ما یک چک باکس برای یونیکد داریم. بنابراین در حال حاضر، source ما، یونیکد هست و destination مون به صورت unicodeهست و این باید خیلی هموار و منطقی تر اجرا بشه.
دوباره ما از طریق wizard جلو میریم و روی next کلیک میکنیم و دوباره next، دقت کنین که در این صفحه، ما قبلا در قسمت source table ، person.person رو انتخاب کرده بودیم، دستگاه این اطلاعات رو نگه نداشته، بنابراین دوباره باید بریم و اون رو انتخاب کنیم. در اینجا ما روی Person.Person میریم. روی next کلیک میکنم، run immediately، next، و finish.
طوری که الان به چک مارکهای سبز رسیدیم. این بیشتر از export های قبلی مون طول کشید، شاید نه به دلیل تبدیل به یونیکد، بلکه به دلیل تعداد زیاد جداول، که همزمان اینبار داریم export میکنیم.
در نهایت، ما به یک چک مارک بزرگ در بالا با یک پیام موفقیت رسیدیم. بنابراین من پنجرهSQL server import and export wizard رو میبندم و میرم و به داده ای که export شده بود، یک نگاهی میندازم.
PersonExport.txt، ما اون رو باز میکنیم، و داده های زیادی رو در اونجا میبینیم. همه اینها به نظر میرسه که خوبن، و روی اولین خط، بعضی از داده های unicode رو میبینم.
A با علامت لهجه ای رو در اکثر سطر ها می بینیم و همونطور که می دونید این همون چیزی هست که به صورت معمول با داده non-unicode، پشتیبانی نمیشه.
اون تنها با شرایط موجود در UNICODE پشتیبانی میشه. بنابراین این به نظر میرسه که به صورت موفقیت امیز هست. باز هم، ممکن هست که من ارورهایی رو توی ویزارد import و export دریافت کنم، اما تجربه من به طور قطع، این هست که شایعترین دلیل ارورها، سعی در تبدیل از unicode به non-unicode هست یا بلعکس. بنابراین من میخوام به source و destination ام نگاه کنم و در صورت امکان، اونها رو با هم مطابقت بدم که ایا اونها هر دو UNICOD هستن یا NON-UNICOD.